 Sparse Auxiliary Networks for Unified Monocular Depth Prediction and Completion - V. Guizilini, R. Ambrus, W. Burgard, A. Gaidon - CVPR 2021 - June 19, 2021. Learning a single network for dialable depth perception, with or without sparse LiDAR input.
Sparse Auxiliary Networks for Unified Monocular Depth Prediction and Completion - V. Guizilini, R. Ambrus, W. Burgard, A. Gaidon - CVPR 2021 - June 19, 2021. Learning a single network for dialable depth perception, with or without sparse LiDAR input. 
Selected Publications
List below updated (very) infrequently, but you can find all my publications on arxiv or my Google Scholar profile.
Sparse Auxiliary Networks for Unified Monocular Depth Prediction and Completion - V. Guizilini, R. Ambrus, W. Burgard, A. Gaidon - CVPR 2021 - June 19, 2021. Learning a single network for dialable depth perception, with or without sparse LiDAR input.  Hierarchical Lovasz Embeddings for Proposal-free Panoptic Segmentation - T. Kerola, J. Li, A. Kanehira, Y. Kudo, A. Vallet, A. Gaidon - CVPR 2021 - June 19, 2021. We learn per pixel feature vectors that simultaneously encode instance- and category-level discriminative information.
Hierarchical Lovasz Embeddings for Proposal-free Panoptic Segmentation - T. Kerola, J. Li, A. Kanehira, Y. Kudo, A. Vallet, A. Gaidon - CVPR 2021 - June 19, 2021. We learn per pixel feature vectors that simultaneously encode instance- and category-level discriminative information. 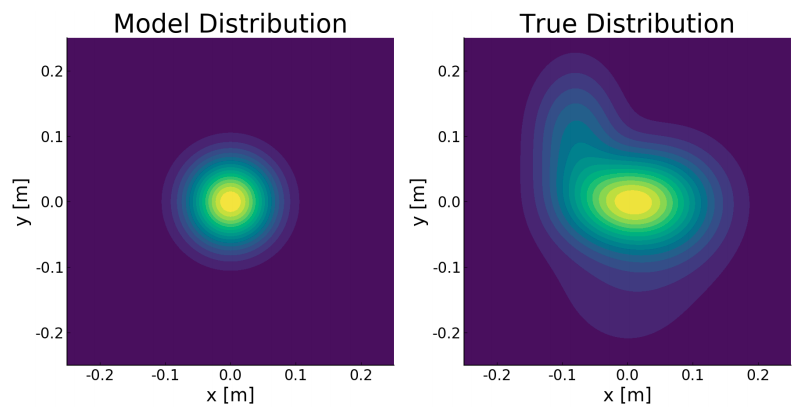 RAT iLQR: A Risk Auto-Tuning Controller to Optimally Account for Stochastic Model Mismatch - H. Nishimura, N. Mehr, A. Gaidon, M. Schwager - RA-L 2021 - January 30, 2021.
RAT iLQR: A Risk Auto-Tuning Controller to Optimally Account for Stochastic Model Mismatch - H. Nishimura, N. Mehr, A. Gaidon, M. Schwager - RA-L 2021 - January 30, 2021.  Monocular Depth Estimation for Soft Visuotactile Sensors - R. Ambrus*, V. Guizilini*, N. Kuppuswamy*, A. Beaulieu, A. Gaidon, A. Alspach - RoboSoft 2021 - January 22, 2021. We show monocular depth estimation methods can work inside small fluid-filled visuotactile sensors like Soft-Bubbles.
Monocular Depth Estimation for Soft Visuotactile Sensors - R. Ambrus*, V. Guizilini*, N. Kuppuswamy*, A. Beaulieu, A. Gaidon, A. Alspach - RoboSoft 2021 - January 22, 2021. We show monocular depth estimation methods can work inside small fluid-filled visuotactile sensors like Soft-Bubbles. 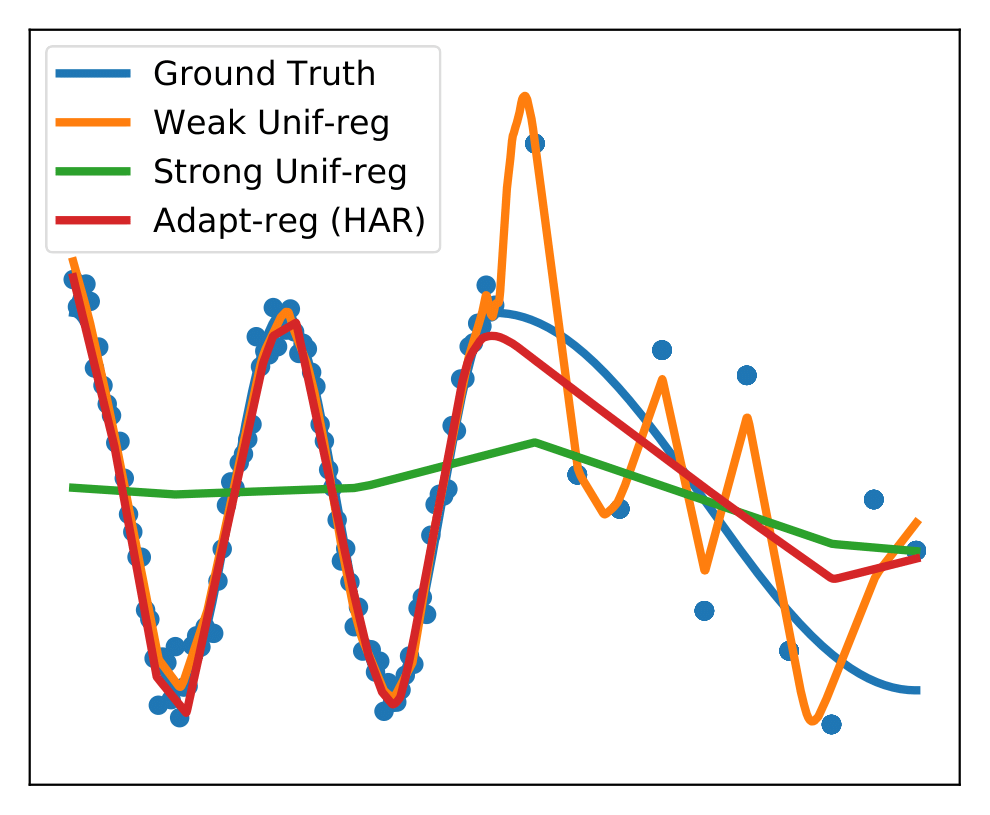 Heteroskedastic and Imbalanced Deep Learning with Adaptive Regularization - K. Cao, Y. Chen, J. Lu, N. Arechiga, A. Gaidon, T. Ma - ICLR 2021 - January 12, 2021. We propose a data-dependent regularization technique for heteroskedastic and imbalanced datasets.
Heteroskedastic and Imbalanced Deep Learning with Adaptive Regularization - K. Cao, Y. Chen, J. Lu, N. Arechiga, A. Gaidon, T. Ma - ICLR 2021 - January 12, 2021. We propose a data-dependent regularization technique for heteroskedastic and imbalanced datasets. 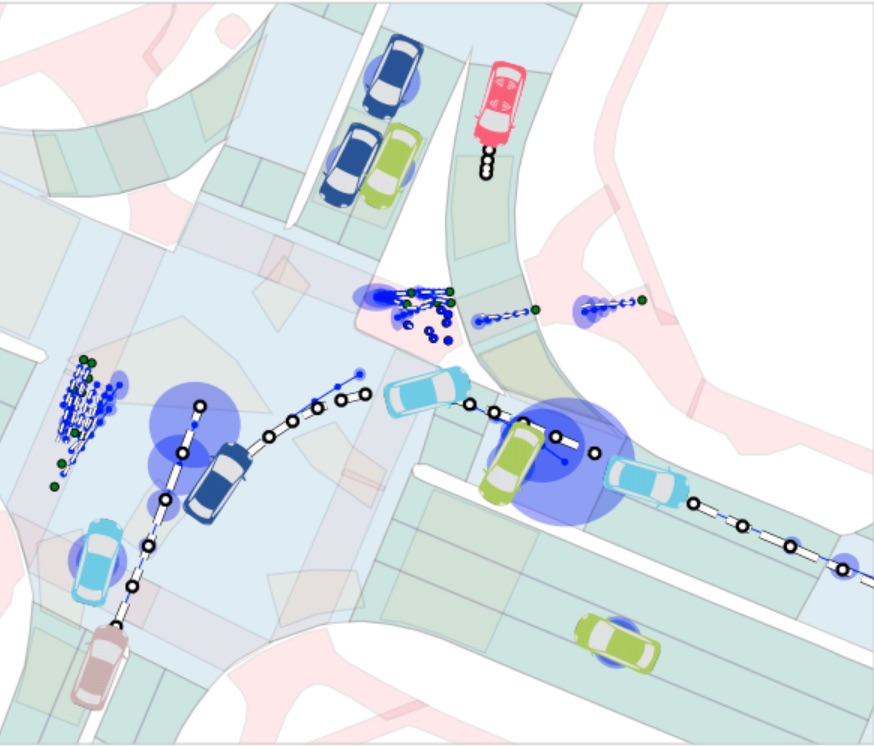 MATS: An Interpretable Trajectory Forecasting Representation for Planning and Control - B. Ivanovic, A. Elhafsi, G. Rosman, A. Gaidon, M. Pavone - CoRL 2020 - November 16, 2020.
MATS: An Interpretable Trajectory Forecasting Representation for Planning and Control - B. Ivanovic, A. Elhafsi, G. Rosman, A. Gaidon, M. Pavone - CoRL 2020 - November 16, 2020.  Self-Supervised 3D Keypoint Learning for Ego-Motion Estimation - J. Tang, R. Ambrus, V. Guizilini, S. Pillai, H. Kim, P. Jensfelt, A. Gaidon - CoRL 2020 (oral) - November 16, 2020.
Self-Supervised 3D Keypoint Learning for Ego-Motion Estimation - J. Tang, R. Ambrus, V. Guizilini, S. Pillai, H. Kim, P. Jensfelt, A. Gaidon - CoRL 2020 (oral) - November 16, 2020. 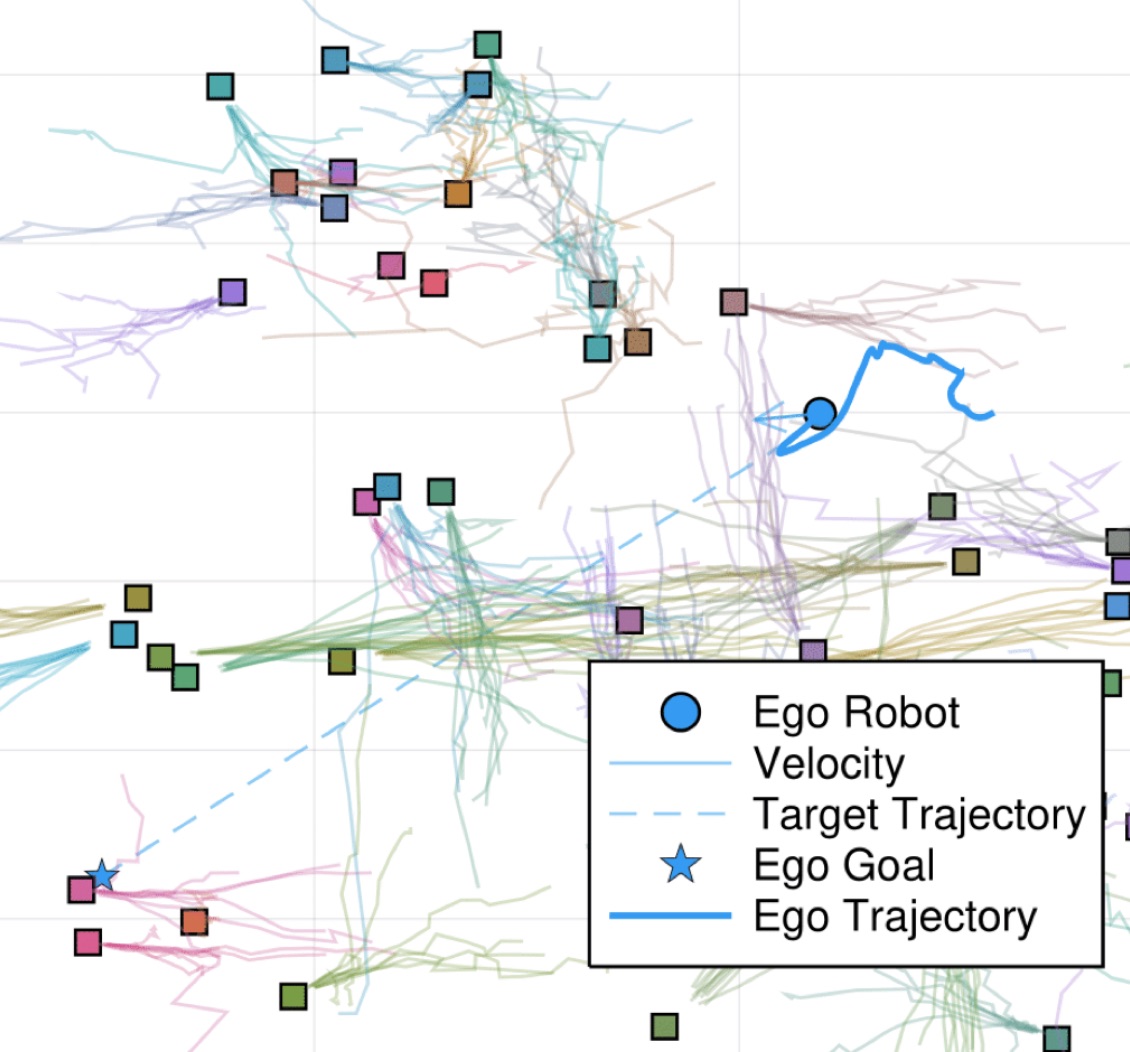 Risk-Sensitive Sequential Action Control with Multi-Modal Human Trajectory Forecasting for Safe Crowd-Robot Interaction - H. Nishimura, B. Ivanovic, A. Gaidon, M. Pavone, M. Schwager - IROS 2020 - October 25, 2020. An online framework for safe and efficient crowd-robot interaction using sampling based trajectory forecasting with risk-sensitive optimal control.
Risk-Sensitive Sequential Action Control with Multi-Modal Human Trajectory Forecasting for Safe Crowd-Robot Interaction - H. Nishimura, B. Ivanovic, A. Gaidon, M. Pavone, M. Schwager - IROS 2020 - October 25, 2020. An online framework for safe and efficient crowd-robot interaction using sampling based trajectory forecasting with risk-sensitive optimal control. 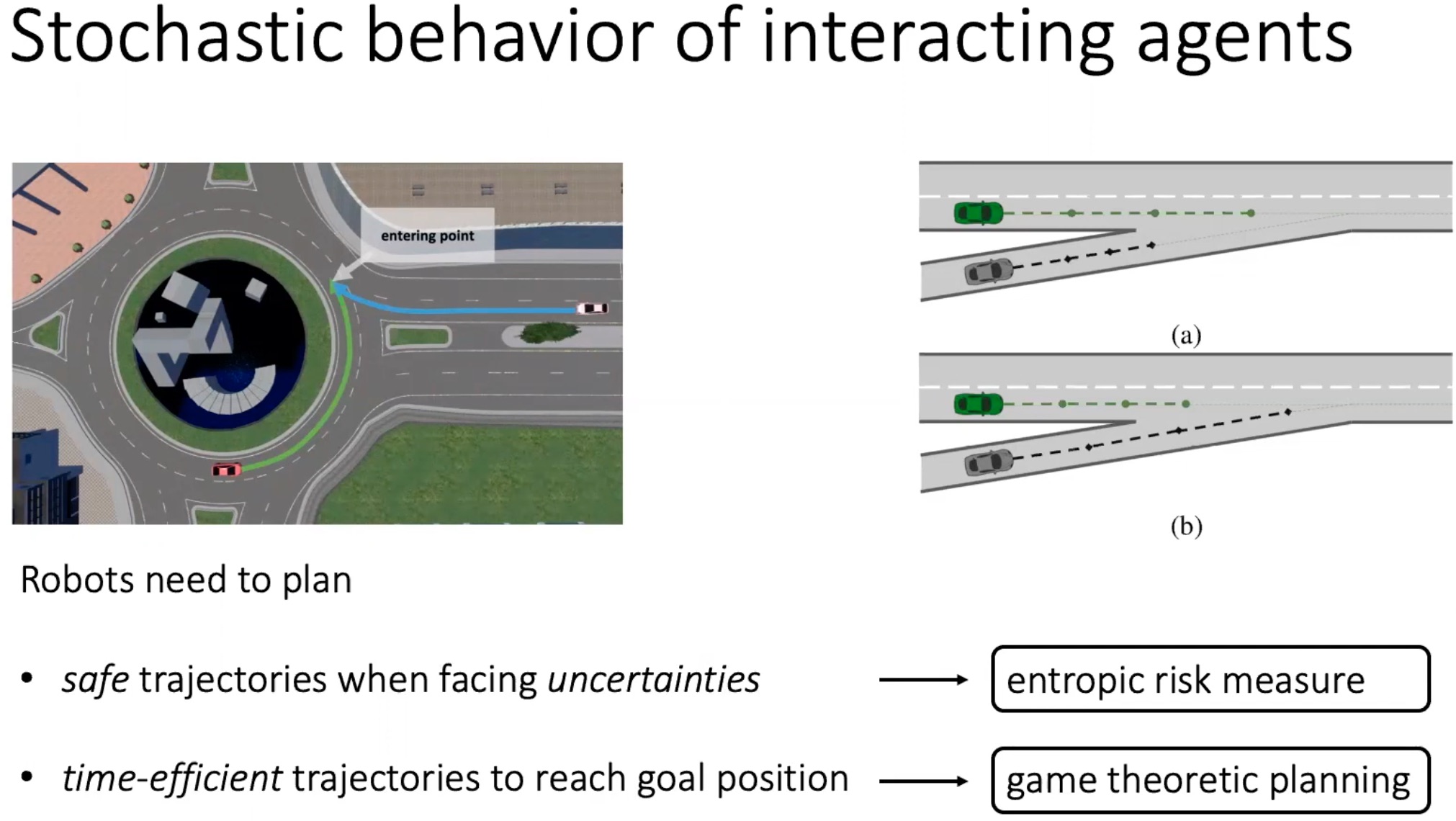 Game-Theoretic Planning for Risk-Aware Interactive Agents - M. Wang, N. Mehr, A. Gaidon, M. Schwager - IROS 2020 - October 25, 2020. A risk-sensitive game-theoretic planning algorithm to model complex multi-agent interactions yielding more time-efficient, intuitive, and safe behaviors when facing underlying risks and uncertainty.
Game-Theoretic Planning for Risk-Aware Interactive Agents - M. Wang, N. Mehr, A. Gaidon, M. Schwager - IROS 2020 - October 25, 2020. A risk-sensitive game-theoretic planning algorithm to model complex multi-agent interactions yielding more time-efficient, intuitive, and safe behaviors when facing underlying risks and uncertainty. 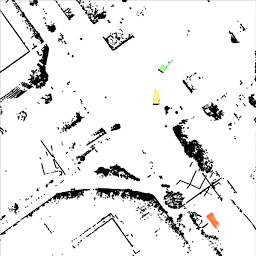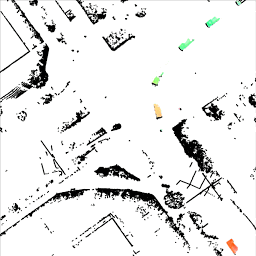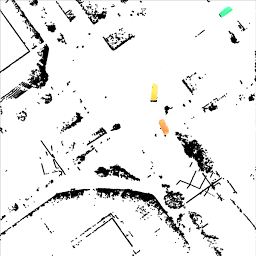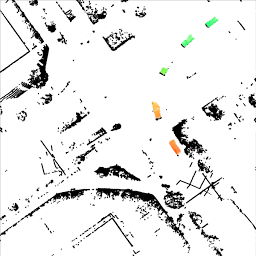 End-to-end Birds-eye-view Flow Estimation for Autonomous Driving - KH. Lee, M. Kliemann, A. Gaidon, J. Li, C. Fang, S. Pillai, W. Burgard - IROS 2020 - October 25, 2020. An end-to-end deep learning framework for LIDAR-based flow estimation in 2.5D bird’s eye view (BeV). We show it boosts tracking performance on a real-world autonomous car.
End-to-end Birds-eye-view Flow Estimation for Autonomous Driving - KH. Lee, M. Kliemann, A. Gaidon, J. Li, C. Fang, S. Pillai, W. Burgard - IROS 2020 - October 25, 2020. An end-to-end deep learning framework for LIDAR-based flow estimation in 2.5D bird’s eye view (BeV). We show it boosts tracking performance on a real-world autonomous car. 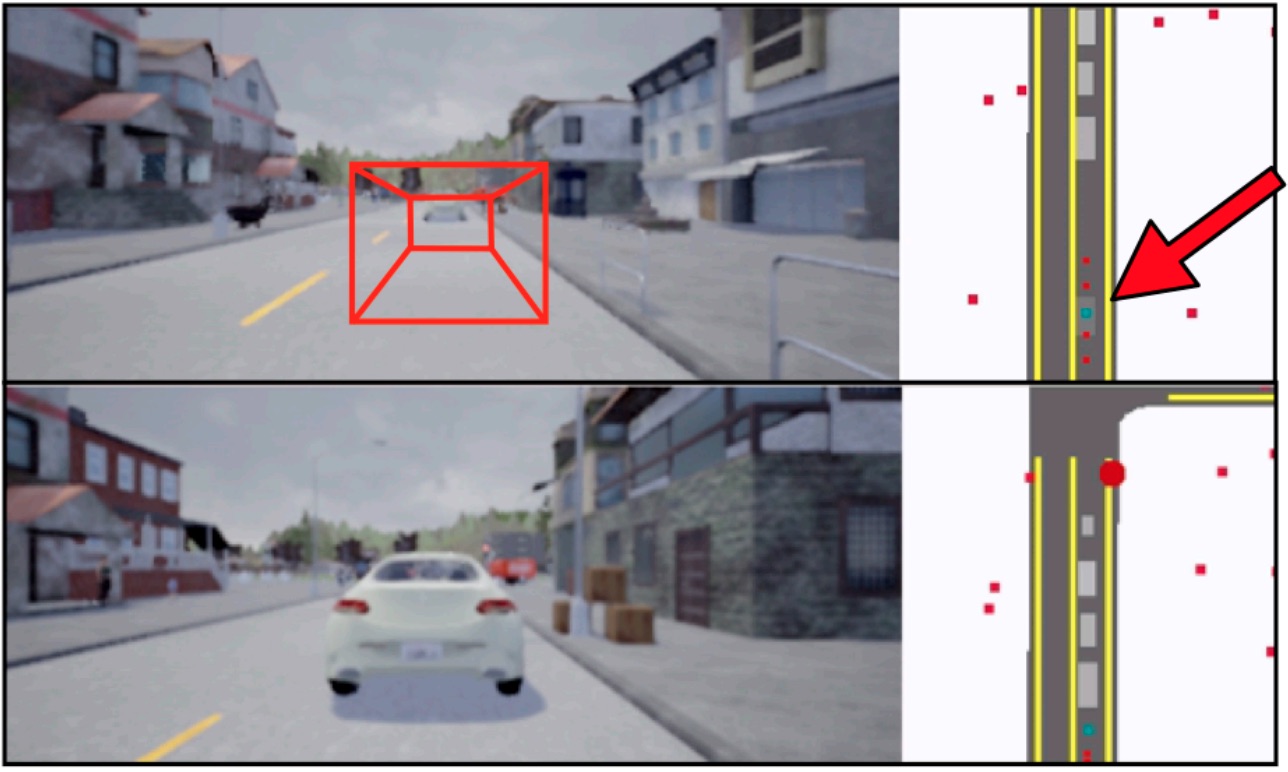 Driving Through Ghosts: Behavioral Cloning with False Positives - A. Bühler, A. Gaidon, A. Cramariuc, R. Ambrus, G. Rosman, W. Burgard - IROS 2020 - October 25, 2020. A novel representation of perceptual uncertainty for learning to plan via behaviorial cloning.
Driving Through Ghosts: Behavioral Cloning with False Positives - A. Bühler, A. Gaidon, A. Cramariuc, R. Ambrus, G. Rosman, W. Burgard - IROS 2020 - October 25, 2020. A novel representation of perceptual uncertainty for learning to plan via behaviorial cloning. 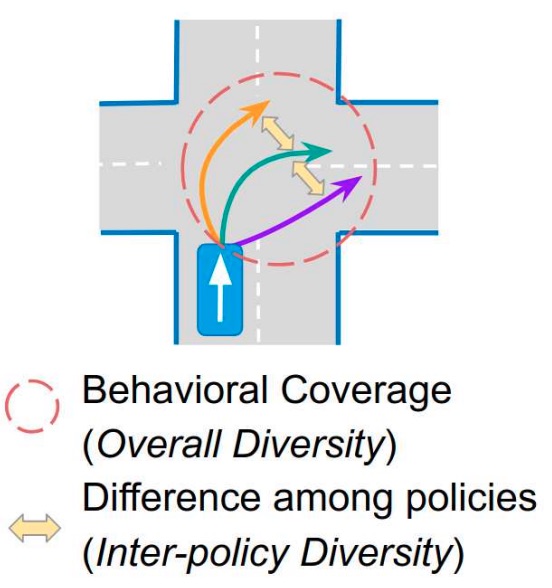 Behaviorally Diverse Traffic Simulation via Reinforcement Learning - S. Shiroshita, S. Maruyama, D. Nishiyama, M. Ynocente Castro, K. Hamzaoui, G. Rosman, J. DeCastro, KH. Lee, A. Gaidon - IROS 2020 - October 25, 2020. Reinforcement Learning of autonomous driving agent policies to balance driving skills and behavioral diversity.
Behaviorally Diverse Traffic Simulation via Reinforcement Learning - S. Shiroshita, S. Maruyama, D. Nishiyama, M. Ynocente Castro, K. Hamzaoui, G. Rosman, J. DeCastro, KH. Lee, A. Gaidon - IROS 2020 - October 25, 2020. Reinforcement Learning of autonomous driving agent policies to balance driving skills and behavioral diversity. 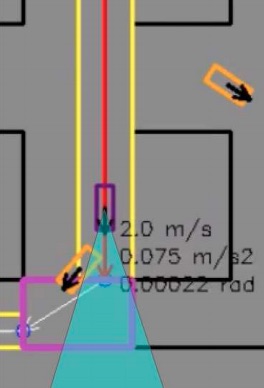 Discovering Avoidable Planner Failures of Autonomous Vehicles using Counterfactual Analysis in Behaviorally Diverse Simulation - D. Nishiyama, M. Ynocente Castro, S. Maruyama, S. Shiroshita, K. Hamzaoui, Y. Ouyang, G. Rosman, J. DeCastro, KH. Lee, A. Gaidon - ITSC 2020 - September 20, 2020. A method to automatically find planner-specific defects of autonomous vehicles in simulation.
Discovering Avoidable Planner Failures of Autonomous Vehicles using Counterfactual Analysis in Behaviorally Diverse Simulation - D. Nishiyama, M. Ynocente Castro, S. Maruyama, S. Shiroshita, K. Hamzaoui, Y. Ouyang, G. Rosman, J. DeCastro, KH. Lee, A. Gaidon - ITSC 2020 - September 20, 2020. A method to automatically find planner-specific defects of autonomous vehicles in simulation.  It Is Not the Journey but the Destination: Endpoint Conditioned Trajectory Prediction - K. Mangalam, H. Girase, S. Agarwal, K-H. Lee, E. Adeli, J. Malik, A. Gaidon - ECCV 2020 (oral, top 2%) - August 27, 2020. Predicted Endpoint Conditioned Network (PECNet) for flexible human trajectory prediction via endpoint inference.
It Is Not the Journey but the Destination: Endpoint Conditioned Trajectory Prediction - K. Mangalam, H. Girase, S. Agarwal, K-H. Lee, E. Adeli, J. Malik, A. Gaidon - ECCV 2020 (oral, top 2%) - August 27, 2020. Predicted Endpoint Conditioned Network (PECNet) for flexible human trajectory prediction via endpoint inference.  Monocular Differentiable Rendering for Self-Supervised 3D Object Detection - D. Beker, H. Kato, MA. Morariu, T. Ando, T. Matsuoka, W. Kehl, A. Gaidon - ECCV 2020 - August 23, 2020. Novel self-supervised method for textured 3D shape reconstruction and pose estimation of rigid objects with the help of strong shape priors and 2D instance masks.
Monocular Differentiable Rendering for Self-Supervised 3D Object Detection - D. Beker, H. Kato, MA. Morariu, T. Ando, T. Matsuoka, W. Kehl, A. Gaidon - ECCV 2020 - August 23, 2020. Novel self-supervised method for textured 3D shape reconstruction and pose estimation of rigid objects with the help of strong shape priors and 2D instance masks.  Neural Ray Surfaces for Self-Supervised Learning of Depth and Ego-motion - I. Vasiljevic, V. Guizilini, R. Ambrus, S. Pillai, W. Burgard, G. Shakhnarovich, A. Gaidon - 3DV 2020 (oral) - August 15, 2020. Neural Ray Surfaces (NRS) are convolutional networks that represent pixel-wise projection rays, approximating a wide range of cameras. NRS are fully differentiable and can be learned end-to-end from unlabeled raw videos.
Neural Ray Surfaces for Self-Supervised Learning of Depth and Ego-motion - I. Vasiljevic, V. Guizilini, R. Ambrus, S. Pillai, W. Burgard, G. Shakhnarovich, A. Gaidon - 3DV 2020 (oral) - August 15, 2020. Neural Ray Surfaces (NRS) are convolutional networks that represent pixel-wise projection rays, approximating a wide range of cameras. NRS are fully differentiable and can be learned end-to-end from unlabeled raw videos. 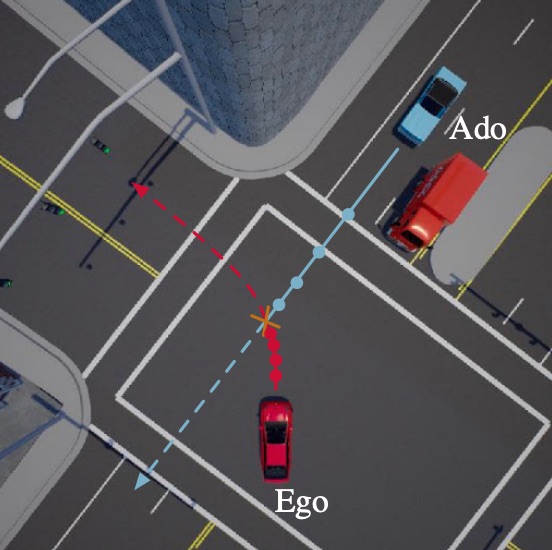 Reinforcement Learning based Control of Imitative Policies for Near-Accident Driving - Z. Cao, E. Biyik, W. Z. Wang, A. Raventos, A. Gaidon, G. Rosman, D. Sadigh - RSS 2020 - July 15, 2020. A hierarchical reinforcement and imitation learning (H-ReIL) approach for learning to drive in near-accident scenarios.
Reinforcement Learning based Control of Imitative Policies for Near-Accident Driving - Z. Cao, E. Biyik, W. Z. Wang, A. Raventos, A. Gaidon, G. Rosman, D. Sadigh - RSS 2020 - July 15, 2020. A hierarchical reinforcement and imitation learning (H-ReIL) approach for learning to drive in near-accident scenarios. 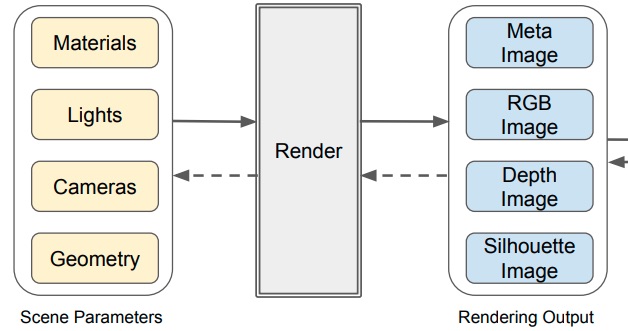 Differentiable Rendering: A Survey - H. Kato, D. Beker, M. Morariu, T. Ando, T. Matsuoka, W. Kehl, A. Gaidon - arXiv - June 22, 2020. A review of the literature and current state of differentiable rendering, its applications, and open research problems.
Differentiable Rendering: A Survey - H. Kato, D. Beker, M. Morariu, T. Ando, T. Matsuoka, W. Kehl, A. Gaidon - arXiv - June 22, 2020. A review of the literature and current state of differentiable rendering, its applications, and open research problems.  Spatio-Temporal Graph for Video Captioning with Knowledge Distillation - B. Pan, H. Cai, DA Huang, KH Lee, A. Gaidon, E. Adeli, JC Niebles - CVPR 2020 - June 16, 2020. A model that learns to distill spatio-temporal object interactions for video captioning.
Spatio-Temporal Graph for Video Captioning with Knowledge Distillation - B. Pan, H. Cai, DA Huang, KH Lee, A. Gaidon, E. Adeli, JC Niebles - CVPR 2020 - June 16, 2020. A model that learns to distill spatio-temporal object interactions for video captioning. 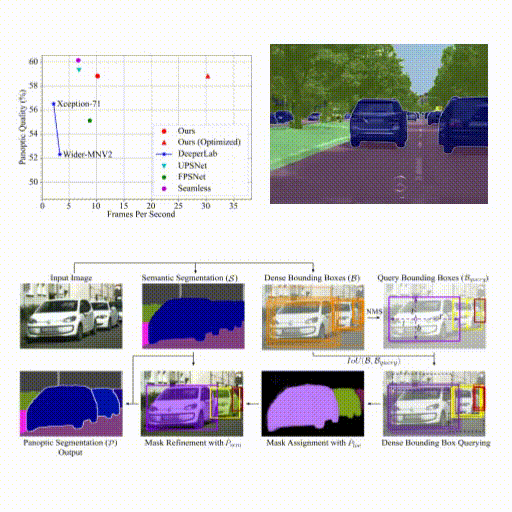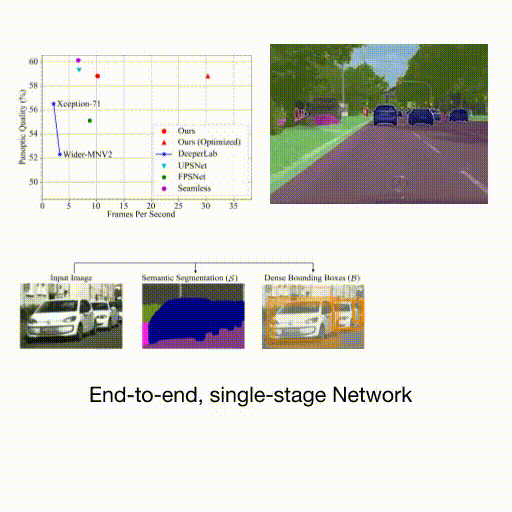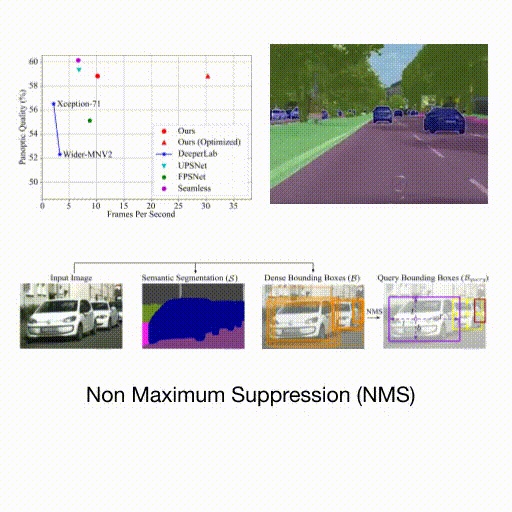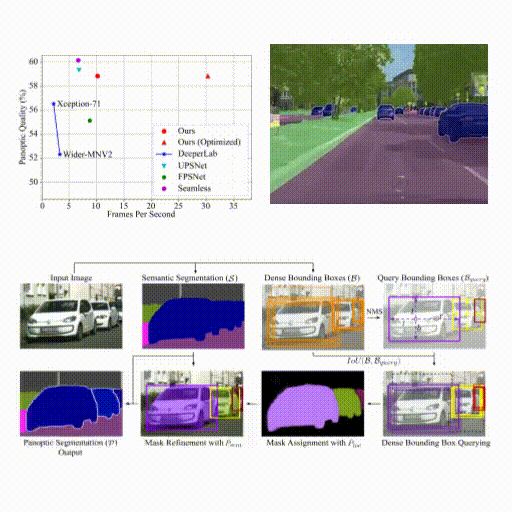 Real-Time Panoptic Segmentation from Dense Detections - R. Hou, J. Li, A. Bhargava, A. Raventos, V. Guizilini, C. Fang, J Lynch, A. Gaidon - CVPR 2020 (oral, top 5.7%) - June 16, 2020. A novel panoptic segmentation method featuring parameter-free instance mask reconstruction, state-of-the-art accuracy, and real-time inference.
Real-Time Panoptic Segmentation from Dense Detections - R. Hou, J. Li, A. Bhargava, A. Raventos, V. Guizilini, C. Fang, J Lynch, A. Gaidon - CVPR 2020 (oral, top 5.7%) - June 16, 2020. A novel panoptic segmentation method featuring parameter-free instance mask reconstruction, state-of-the-art accuracy, and real-time inference.  Autolabeling 3D Objects with Differentiable Rendering of SDF Shape Priors” - S. Zakharov, W. Kehl, A. Bhargava, A. Gaidon - CVPR 2020 (oral, top 5.7%) - June 16, 2020. An automatic annotation pipeline to recover 9D cuboids and 3D shapes from pre-trained off-the-shelf 2D detectors and sparse LIDAR data.
Autolabeling 3D Objects with Differentiable Rendering of SDF Shape Priors” - S. Zakharov, W. Kehl, A. Bhargava, A. Gaidon - CVPR 2020 (oral, top 5.7%) - June 16, 2020. An automatic annotation pipeline to recover 9D cuboids and 3D shapes from pre-trained off-the-shelf 2D detectors and sparse LIDAR data.  3D Packing for Self-Supervised Monocular Depth Estimation - V. Guizilini, R. Ambrus, S. Pillai, A. Raventos, A. Gaidon - CVPR 2020 (oral, top 5.7%) - June 16, 2020. A new state of the art in self-supervised monocular depth estimation (PackNet), a new benchmark (DDAD), and weak velocity supervision.
3D Packing for Self-Supervised Monocular Depth Estimation - V. Guizilini, R. Ambrus, S. Pillai, A. Raventos, A. Gaidon - CVPR 2020 (oral, top 5.7%) - June 16, 2020. A new state of the art in self-supervised monocular depth estimation (PackNet), a new benchmark (DDAD), and weak velocity supervision. 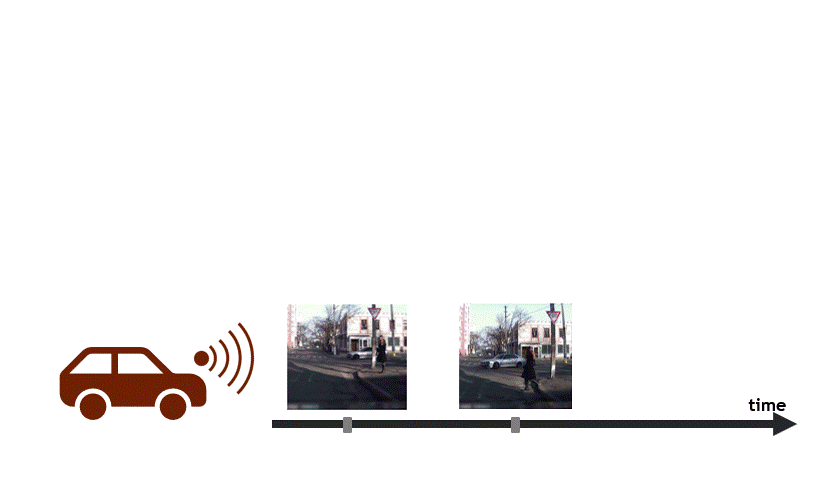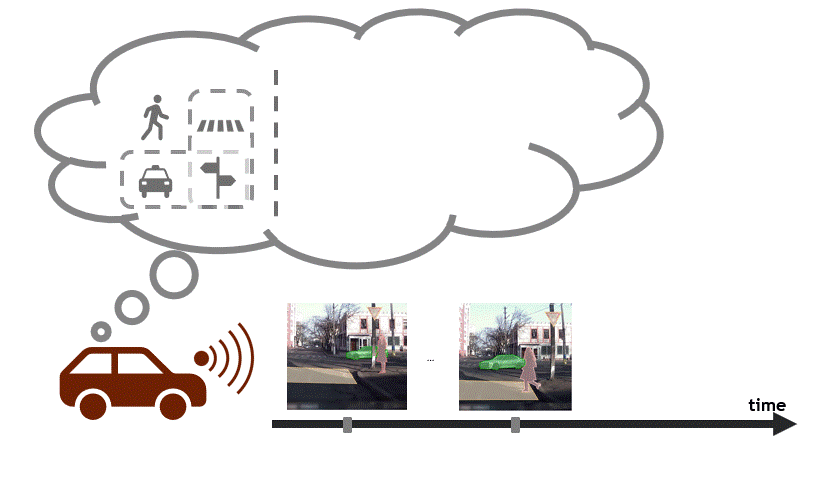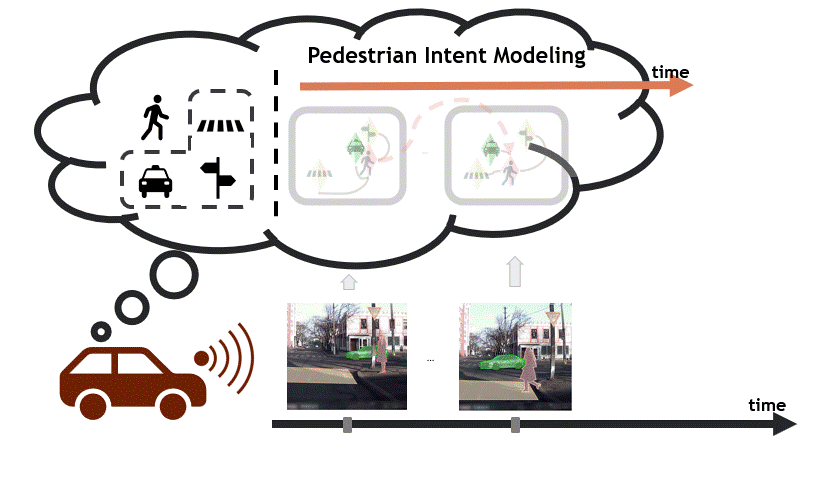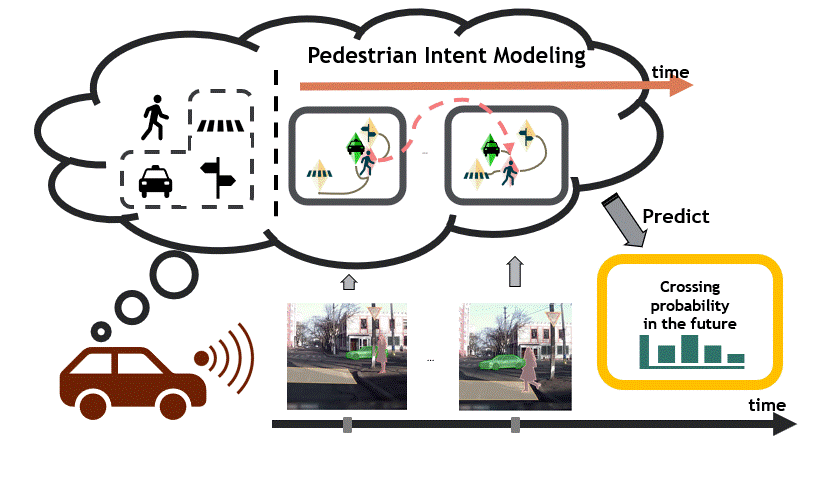 Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction - B. Liu, E. Adeli, Z. Cao, KH Lee, A. Shenoi, A. Gaidon, JC Niebles - RA-L & ICRA 2020 - May 31, 2020. A new dataset (STIP) and graph neural network operating on scene graphs to predict pedestrian crossing intent.
Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction - B. Liu, E. Adeli, Z. Cao, KH Lee, A. Shenoi, A. Gaidon, JC Niebles - RA-L & ICRA 2020 - May 31, 2020. A new dataset (STIP) and graph neural network operating on scene graphs to predict pedestrian crossing intent.  Semantically-Guided Representation Learning for Self-Supervised Monocular Depth - V. Guizilini, R. Hou, J. Li, R. Ambrus, A. Gaidon - ICLR 2020 - April 26, 2020. A new architecture leveraging fixed pretrained semantic segmentation networks to guide self-supervised representation learning via pixel-adaptive convolutions.
Semantically-Guided Representation Learning for Self-Supervised Monocular Depth - V. Guizilini, R. Hou, J. Li, R. Ambrus, A. Gaidon - ICLR 2020 - April 26, 2020. A new architecture leveraging fixed pretrained semantic segmentation networks to guide self-supervised representation learning via pixel-adaptive convolutions.